Fedora 10으로 업그레이드
회사에 프로젝트 때문에 리눅스 서버를 한대 설치하던 중
페도라가 벌써 10 버전이나 되었더라.
(8버전 사용중)
음 그래서 집에 테스트 서버를 업그레이드 해보기로 했다.
그리고 역시 yum을 이용하면 간단해^^
# wget ftp://download.fedora.redhat.com/pub/fedora/linux/releases/10/Fedora/x86_64/os/Packages/fedora-release-10-1.noarch.rpm
# wget ftp://download.fedora.redhat.com/pub/fedora/linux/releases/10/Fedora/x86_64/os/Packages/fedora-release-notes-10.0.0-1.noarch.rpm
# rpm -Uvh fedora-release-10-1.noarch.rpm fedora-release-notes-10.0.0-1.noarch.rpm
# yum clean all
# yum upgrade
하면 바로 업그레이드 시작!! 중간 중간에 디펜던시 에러나는 패키지들을 일단 과감하게 삭제… 물론 운영 중인 서비스와 관계 된다면 대략 난감이겠지만.
집에 PC 테스트하는 개인 PC이므로!! 고고씽!!
그리고 2기가 다운로드 와 업데이트!! 반나절 정도 걸리는걸

업그레이드 끝!!
'OS, DB > Linux,Unix' 카테고리의 다른 글
| grep 를 이용해 텍스트 내용 검색 (0) | 2009.09.30 |
|---|---|
| Fedora 10용 Freshrpm 추가하기 (0) | 2008.12.19 |
| VMWare Linux에서 설치가 안될때... (0) | 2008.02.20 |
| fedora Linux yum 국내 reso (0) | 2007.12.12 |
| 리눅스 데스크탑 소프트웨어 - 피카사... (0) | 2007.12.09 |
Windows Live Writer 베타
요즘에 집에서 블로그를 위해서 가장 많이 쓰는 프로그램은 Windows Live Writer인데…
요것이 항상 아쉬운 부분이 왜 한글은 아직 맞춤법 검사가 되지 않을까? 라는 생각이었다.
그런데… 웹 서핑 중 Windows Live Writer Beta 3 버전에서 한글 맞춤법 검사가 된다는 글을 발견하여
무작정 설치하였다.
[관련 링크:http://www.liveside.net/main/archive/2008/09/16/windows-live-wave-3-betas-download-now.aspx]
Korean
http://g.live.com/1rebeta3/ko/wlsetup-web.exe
http://g.live.com/1rebeta3/ko/wlsetup-all.exe

오 UI도 깔끔한데… 이제 베타 티만 내지 않으면 최고인데… 아직까지는 특별히 발견한 문제점은 없는 것 같다.

한글 맞춤법 검사

아직까지는 맘에 드는걸^^
'OS, DB > MS Windows' 카테고리의 다른 글
| Windows 7 XP 모드 설치하기 (7) | 2009.11.21 |
|---|---|
| 윈도우 서비스 관련 TIP (0) | 2009.02.26 |
| MS installer 기본 명령줄 인수 (0) | 2008.11.03 |
| RDPDD.dll 오류로 터미널이 되지 않을때 (0) | 2008.10.08 |
| 불법 윈도 XP는 '검정 바탕화면' (0) | 2008.09.24 |
MS installer 기본 명령줄 인수
| • | /Q - 자동 모드를 사용하거나 파일 압축을 풀 때 메시지를 표시하지 않습니다. |
| • | /Q:U – 사용자 개입 자동 모드를 사용합니다. 사용자 개입 자동 모드는 사용자에게 일부 대화 상자를 표시합니다. |
| • | /Q:A – 관리자 개입 자동 모드를 사용합니다. 관리자 개입 자동 모드는 사용자에게 대화 상자를 표시하지 않습니다. |
| • | /T: path - 설치 프로그램에서 사용되는 임시 폴더나 파일을 추출하기 위한 대상 폴더(/c 스위치를 사용할 경우)의 위치를 지정합니다. |
| • | /C - 설치하지 않고 파일 압축을 풉니다. /t: 경로가 지정되지 않은 경우 대상 폴더를 만들 것인지 묻습니다. |
| • | /C: cmd - 이 도구를 설치하는 데 사용할 대체 Setup .inf 파일이나 .exe 파일의 경로와 이름을 지정합니다. |
| • | /R:N – 설치 후 컴퓨터를 다시 시작하지 않습니다. |
| • | /R:I – 이 스위치를 /q:a 스위치와 함께 사용할 때를 제외하고 컴퓨터를 다시 시작해야 하는 경우 사용자에게 다시 시작할 것인지 묻습니다. |
| • | /R:A – 설치 후 항상 컴퓨터를 다시 시작합니다. |
| • | /R:S – 설치 후 사용자에게 메시지를 표시하지 않고 컴퓨터를 다시 시작합니다. |
'OS, DB > MS Windows' 카테고리의 다른 글
| 윈도우 서비스 관련 TIP (0) | 2009.02.26 |
|---|---|
| Windows Live Writer 베타 (2) | 2008.11.11 |
| RDPDD.dll 오류로 터미널이 되지 않을때 (0) | 2008.10.08 |
| 불법 윈도 XP는 '검정 바탕화면' (0) | 2008.09.24 |
| Windows Vista 에서 MSSQL 2005로의 OLE 접속이 무지하게 느릴때.... (0) | 2008.02.13 |
페이징 성능 향상 기법 MSSQL 쿼리
DB 쿼리를 볼일이 있어서 스크랩 함
<출처 : http://blog.naver.com/kikky22?Redirect=Log&logNo=140040666763>
ORCLE이 정말 좋은 RDB라는 것을 알게 하는 것이 바로 페이징 기법일거라 생각되네요.
MySQL도 내부적으로 페이징이 가능한 쿼리를 지원해주지만 MSSQL은 최근 2005버전까지도... 좋은 페이징 기법을 소개하지 못하고 있는 것 같네요. 성능 좋은 페이징 기법이 공개된 것이 있기도 하지만... 초심자에게 쉽지 않은 쿼리들인 것 같습니다.
이에 조금 쉽게... 어떻게 하면 성능이 향상되는지를 설명해 보려고 합니다.
아래의 내용은 온라인상에서 바로 작성하는 내용이고 맞춤법등이 틀릴 수 있기 때문에 copy해서 사용하지 마시기 바랍니다.
개념을 잡는 정도로 활용하시면 좋을 것 같습니다.
MS SQL의 페이징 기법의 키는 TOP 키워드입니다.
#1. TOP과 클러스터드 인덱스
SELECT TOP 10 ID, subject, contents FROM TBL
이 쿼리는 누구나 알고 있는 쿼리입니다. 여기서 중요한 것이 TOP 10 입니다. 상위 10개만 갖고 오겠다는 뜻입니다.MSSQL은 내용저장을 클러스터드 인덱스 순으로 저장을 하게 됩니다. 만약 ID를 PK로 지정하셨거나 따로 클러스터드 인덱스로써 ID를 지정해 놓으셨다면 ID순으로 자동으로 정렬이 되어 상위 10개만 가져오게 됩니다.
기본키는 반드시 설정할 필요는 없습니다. 다만 레코드를 구분하는 아이디값을 대게의 경우 기본키로 놓게 되는데요.
사실 기본키가 성능에 있어서의 의미는 없다고 봅니다.(확인된 바 없음)
기본키는 자동으로 인덱스 컬럼이 된다는게 의미가 있겠죠. 그것도 테이블당 딱 하나 사용할 수 있는 클러스터드 인덱스로 자동 설정됩니다. 헌데 문제는 ASC로 설정된다는 것입니다.
웹페이지에서 최근 글의 경우는 대부분 DESC로 정렬합니다. 즉 최근 글을 먼저 표시해주지요. PK로 만들더라도 꼭 ID를 DESC로 인덱스하도록 만들어야 합니다.
바로 이 유일 인덱스 컬럼이 성능을 좌우하는 핵입니다.
초심자의 경우 인덱스의 중요성을 넘기는 경우가 많은데요. PK가 중요한 것이 아니라 정렬을 원하는 컬럼을 클러스터드 인덱스로 만들어 놓는 것이 성능에 가장 중요합니다.(레코드 수가 늘 수록 엄청난 성능 향상이 있습니다.)
팁) TOP 10 PERCENT라는 키워드도 가능합니다. 말 그대로 전체의 10%만 가져온다는 것입니다. 쓸모가 많은 팁이라 생각되네요.
#2. 가장 많이 쓰이는 페이징 쿼리
SELECT TOP 10 ID, subject, contents FROM TBL where ID not in (SELECT TOP 현재페이진 이전까지의 모든 게시물 수 ID FROM TBL order by ID DESC) order by DESC
참 좋은 쿼리입니다. MS SQL에서 나올 수 있는 가장 간결하고 좋은 쿼리가 아닌가 싶습니다.
저역시 작은 규모의 게시판 종류는 무조건 이 쿼리를 이용합니다. 유지보수가 편하기 때문입니다. 누구나 쉽게 알아 볼 수 있기 때문에 제가 도저히 못 봐줄 유지보수 프로젝트라면 다른 사람이 대신할 수 있는 쿼리이기 때문에... 이 쿼리를 즐겨사용합니다.
다만 이 쿼리에는 조건이 하나 붙습니다.
사용자들이 100페이징 이하(게시물 수로 2000개 이하정도)의 글을 되도록 조회한다.
이 쿼리는 2만건 이하의 테이블에 적당하다고 생각됩니다.
1페이지라고 하면 성능이 최고가 되며
2페이지라면 not in 안의 쿼리문에 의해 한페이지가 10개의 글이라고 가정하면 10개를 일단 불러 들이게 됩니다. 제거를 위해서죠.
3페이지라면 20개를 불러들여서 제거를 해야 하겠고
4페이지라면 30개를...
그럼 100페이지라면 990개의 글을 읽어 들여야 겠군요. 990개를 먼저 불러 들이는 것이 문제입니다.
가장 심플한 쿼리이지만 DB에 어느정도의 부하를 주는 쿼리라는 것을 알 수 있습니다.
개인적으로 레코드셋종류의 객체에 내용을 불러오는 쿼리는 0.1초 이전에 끝나야 한다고 생각됩니다. 물론 검색이 들어가면 이야기가 달라지지만 기본적인 형태(아무런 검색이 없는 경우)에서는 0.1초 이하에서 OPEN을 끝내는 것이 좋다고 생각되네요.
#3. ORDER BY문
아시다시피 ORDER BY문은 정렬의 조건입니다. 위 쿼리의 경우 ORDER BY ID DESC이니깐 ID에 대해 내림차순으로 정렬하겠네요. 사실 ORDER BY 문은 안써주는 것이 성능에 가장 좋습니다.
만약 ID를 클러스터드 인덱스로 지정해 놨다면 안써도 될 것 같습니다. 클러스터드 인덱스를 내림차순으로 지정해 놨다면 ORDER BY ID DESC는 성능에 전혀 영향을 미치지 않습니다. 가끔 MSSQL에서 서브쿼리를 썼을 경우 원하는 값을 리턴하지 않습니다. 이유는 모르겠습니다. 서브쿼리문을 가져오는 방법에서 더 빨리 가져오려고 하는 그 부분에서 나오는 문제일거라 생각되네요.
클러스터드 인덱스로 지정했을 경우 ORDER BY ID DESC는 되도록이면 넣으시는게 좋습니다. 정확성을 위해서!;
#4. 성능저하 요소 SELECT COUNT(*) FROM TBL
NOT IN 쿼리보다 심플한 페이징 쿼리는 MSSQL에서 없는 것 같습니다. 개발자 입장에서 프로그래밍하기도 정말 쉬운 쿼리입니다. 현재 페이지 번호만 넘겨주면 모든 것이 가능합니다. 가장 큰 장점이 바로 개발하기 편하다는 것이 겠고, 사용자의 웹접근 액션과도 상당히 잘 맞아 떨어집니다. 사람들은 10페이지 이상은 잘 보지 않으려는 경향이 있기 때문입니다.
NOT IN 쿼리는 생각보다 좋은 쿼리라는 것을 일단 말씀 드립니다. 단 조건은 INDEX를 잘 설정해줬다는 조건이 붙습니다.
게시판 등을 개발할 때 전체 게시물 수를 구해오는데 가장 많이 쓰는 쿼리문이 SELECT COUNT(*) FROM TBL입니다. 페이지 바로 가기 버튼을 위해서도 필요하고 게시물 번호를 붙히는 데도 쓰이기 때문에 쓰는 경우가 많습니다.
헌데 이 쿼리문 속도가 상당히 늦습니다. 100만건을 조회할 경우 1초가 넘어가 버리는 무식한 쿼리입니다. 야야~ 그럼 IDEX행을 가져와봐... 라고 하실 것 같습니다. SELECT COUNT(ID) FROM TBL ... 허나 애석하게 속도가 똑같습니다.
그리고 COUNT함수는 가능하면 (*)를 사용하시기 바랍니다. 이것이 정확한 방법입니다. COUNT(*)에서 속도향상을 위한 방법은 솔직히 말씀드려서 없습니다.
가장 좋은 방법은 테이블 하나를 만들어서 데이타 입력/삭제시마다 업데이트 하면서 게시물 수를 저장해 놓는 방법입니다. MSSQL 내에서는 트리거라는 기능을 제공합니다. INPUT/DELETE 시 UPDATE TBL_SETTING set TBL_COUNT = xxx 뭐 이런 식으로 짜 놓으면 되겠죠.
전체 게시물 수를 가져올 때는 되도록이면 트리거를 쓰거나 프로그램을 통해 정보를 저장하는 테이블에 업데이트하고 이 자료를 페이징시 가져오는 것이 성능을 위한 좋은 방법입니다.
1만건 이하라면 COUNT(*)를 쓰던 NOT IN을 쓰던 별 지장이 없다는 게 제 생각입니다. 고로, 자꾸 써먹어도 좋은 쿼리 들임을 일단 알려드립니다.
#5 성능향상에 가장 좋은 방법
1000만건을 테스트 해보지는 않았지만, 1페이지와 100만 페이지가 같은(해보진 않았죠^^)-혹은 비슷한- 성능을 보이는 쿼리는 다름 아닌 NOT IN보다 훨씬 더 간결한 쿼리입니다.
SELECT TOP 11 ID, subject, contents FROM TBL where ID <= 현재페이지 최상위 ID (order by ID DESC)
이 쿼리에서 가장 중요한 것은 ID가 클러스터드 인덱스로 ID를 설정하고 내림차순으로 지정되어 있어야 한다는 것입니다.
아무리 많은 글들도 0.1초안에 해결될만한 가장 성능이 좋은 쿼리문입니다. 동접자수 엄청나고 글 수가 많다면 이방법 이외의 방법은 사용하지 마시기 바랍니다.
허나 장점이 있으면 단점도 있습니다. 이 쿼리를 사용할 경우 ID값에 바로 접근하긴하기 때문에
이전 1 2 3 4 5 6 7 8 9 10 다음 <- 이와 같은 구성이 불가능하다는 것입니다.
그래서 TOP 10이 아닌 11을 사용한 것입니다. 1부터 10까지 구성은 힘들지만 다음페이지 버튼은 가능하기 때문입니다. 갯수가 11개면 다음 페이지가 있다는 이야기가 되며, 다음페이지의 최상위 ID값도 가져올 수 있게 됩니다.
어쨌거나 위 쿼리는 성능에 있어서는 더이상 좋을 수 없는 쿼리입니다. 분명 글이 많고 사용자 액션이 단순한 사이트라면 반드시 고려해보셔야 할 쿼리입니다. 이전 페이지 구현은 프로그램적으로 머리를 좀 굴려야 할 부분이긴 합니다.
어짜피 다음 페이지 버튼을 눌러야만 가능하니깐 이전 페이지의 ID값은 무조건 가지고 갈 수 있습니다. POST방식으로 이전 페이지 정보를 계속 넘기는 방법도 괜찮은 방법일 것입니다.
SELECT TOP 10 ID FROM TBL where ID > 현재페이지 최상위 ID order by ID ASC 를 어쩔 수 없이 쓰는 것도 한 방법이겠구요. 그래도 다른 쿼리들보다는 빠른 방식이니깐요. <- 이건 저도 테스트 해보진 않았습니다.
#6. 사용자 편의성도 좀 생각해 보자
대부분 웹사이트에서는 NOT IN쿼리가 좋은 방법입니다. 사용자 편의성에 있어서 좋은 선택이니깐요.
이전 1 2 3 4 5 6 7 8 9 10 다음 <- 이게 얼마나 편한 방법입니까^^; 그리고 사람들은 10페이지 이상 조회를 거의 하지 않기도 합니다.
성능을 생각한다면 #5번의 방법이 정말 좋은 방법이지요. 다만 사용자 편의를 위한 인터페이스 구현은 사실상 불가능 합니다. 이전 페이지 구현도 쉽지 않죠.
목표가 생겼습니다.
이전 1 2 3 4 5 6 7 8 9 10 다음
이 기능을 한번 구현해 보죠. 약간 성능 저하가 있더라도... 전체 NOT IN보다는 훨씬 더 빠르게 한다는 목표를 가지고...
일단 쿼리를 하나 보죠.
SELECT TOP pageSize*10+1 ID from TBL where ID <= 1페이지 11페이지 21페이지 등 각 1페이지의 처음 ID
이 쿼리는 페이지 바로가기 버튼 구현을 위한 쿼리입니다.
페이지 사이즈가 10개라고 하면 101개를 가져옵니다. 101개면 너무 많지 않냐 하겠지만 적은 갯수입니다.^^
컬럼이 하나밖에 없기 때문에 속도 저하가 거의 없는 쿼리죠.
이 결과를 가지고 1 2 3 4 5 6 7 8 9 10 다음 버튼 구현이 가능합니다. 이전 버튼 구현은 역시 약간 복잡하죠?
PageInfo = rs.getrows() 등의 좋은 메소드 등을 통해 배열로 만든 후 이 기능을 구현하는 것이 가장 좋은 방법일거라 생각됩니다.
SELECT TOP 10 ID, subject, contents from TBL where ID not in(SELECT TOP pageSize*(현재페이지의한자리숫자-1 / 0일때는 10) ID from TBL where ID <= 페이지 11페이지 21페이지 등 각 1페이지의 처음 ID order by ID DESC) and ID <= 페이지 11페이지 21페이지 등 각 1페이지의 처음 ID order by ID DESC
이 쿼리는 실제로 글을 뿌려주는 쿼리입니다. NOT IN이 쓰였네요. 하지만 10페이지 단위로 끊어서 10페이지 글 내에서 NOT IN을 사용하기 때문에 항상 빠른 속도를 내줄 수 있는 쿼리입니다.
페이지당 글 수가 아무리 많아도 100개 이하가 대부분이기 때문에 10페이지 단위로 끊는다고 해도 1000개의 글 내에서 모든 작업이 이루어지기 때문에 성능 저하는 거의(아예) 없다고 보시면 됩니다. 1000개정도 레코드는 아무것도 아니지요.
다만 걸리는 것은 페이지 바로 가기 버튼을 구현하기 위해 비슷한 쿼리를 두번 날렸기 때문에 두배의 비용이 든다는 거겠지요.
#7. 검색에 대한 이야기
검색 속도를 위한 가장 좋은 방법은 고가의 검색 엔진을 사용하는 것입니다. 검색엔진에 DB를 설정하고 URL 저장 방법만 설정해 놓고 스케쥴링만 해 놓으면 검색엔진은 알아서 DB를 검색하고 고쳐진 값에 대해서 URL 링크를 인덱싱해 놓습니다.
속도도 빠르고 한글의 경우 형태소 분석기를 통해 별에 별 검색도 가능하며 서비스 측면에서는 하일라이트 생성기등을 통해 사용자 편의성을 제공해주고... 뭐... 문제는 쩐이군요^^;
MSSQL에서 우리는 like '%xxx%' 검색을 많이 활용하게 됩니다.
SELECT ID, subject, contents from TBL where subject like '%xxx%'
이 쿼리는 xxx를 가지는 모든 subject 컬럼에 대해 검색을 하게 됩니다. 그럼 어떻게 해야 할까요. 넵~ 인덱스를 설정해야 합니다. subject에 대해서 넌클러스터드 인덱스를 설정해 주어야 합니다. 그러면 엄청난 속도 향상을 느낄 수 있습니다.
subject 는 varchar(255)형입니다. 그렇기 때문에 인덱스 설정이 가능합니다.
그럼 contents like '%xxx%'는?
헌데 contents가 text형이거나 varchar(max) (이건 2005에서 지원)라면?...
불행히도 인덱스를 줄수가 없습니다. MSSQL은 그다지 많은 인덱스 공간을 지원해주지 않습니다.
이경우 가능하면 input쪽에 varchar(4000)정도 만큼만 글을 입력하도록 제한하거나 varchar(4000)을 몇개 더 만들어서 DB저장시 나누어서 넣어주는게 좋습니다.
편법이고 지저분한 방법입니다.^^; 그래도 뭐 속도 향상이 있다면야... 모두들 어쩔 수 없이 text형도 검색을 하지만, 좋은 방법이 아닙니다. 글이 1만개만 넘어가다 상당한 부하가 걸릴 거라 생각됩니다.
넌클러스터드 인덱스만이라도 걸려 있다면, 성능은 무척 좋아집니다.
하지만 너무 방법이 지저분 하네요.
더좋은 방법이 있겠죠? MSSQL은 이런 경우를 위해 풀텍스트검색서비스를 지원합니다. varchar(MAX)나 text형 등을 시중의 검색엔진과 비슷한 방식으로 인덱싱하고 검색할 수 있는 방법은 제공합니다. 속도가 그렇게 좋지는 못합니다만... 형태소 분석기도 들어 있고 유사어 검색도 가능하고 정확도 정렬도 가능합니다. 다만 문제는 속도가 생각처럼 나오지는 않는 다는 것입니다. 특히 정확도 정렬을 위한 정렬의 경우 100만건 이상으로 테스트시 1초가 넘어가더군요.
그리고 MSSQL 2000에서 한글은 제대로 지원되지 않았습니다. 2005에서 한글 지원이 되는데... 실제로 띄어쓰기를 하지 않아도 검색이 되는 정도를 확인하였습니다. 동의어 검색도 가능하다고 하는데... 저역시 많은 테스트가 필요할 것 같습니다.
2000에서는 전혀 안쓰는 기능이었지만, 2005에서는 충분히 활용가치가 있을 것 같네요. 다만 호스팅 업체에서 이 기능을 지원하지 않는 다는 것이 가장 큰 문제입니다.^^; 인덱싱 속도는 꽤 빠르나 하드디스크를 많이 차지하기 때문에, 그리고 인덱싱시 꽤 부하를 주기 때문에 지원하지 않는 것 같으며, 2000의 경우 한글 인덱싱 자체가 잘 안되기 때문에 지원을 하지 않는 것 같습니다.
다만 MSSQL 2005라면 프로젝트에 충분히 쓸 수 있을 것도 같습니다. 제가 이번에 활용해보도록 하겠습니다.
상용검색엔진에 비하면 못하겠지만 어느정도 흉내를 내주고 CONTAINS(TABLE)/ FREETEXT(TABLE)등의 4개의 함수를 통해 SQL쿼리문 내에서 사용하기 때문에 개발하기가 수월합니다.
풀텍스트 검색엔진에 대한 이야기는 또 다음에 계속 하도록 하겠습니다.
정리;
속도 향상을 위해 가장 중요한 것은 바로 INDEX 설정!;
'OS, DB > SQL,DB' 카테고리의 다른 글
| 오라클 개행문자 제거하기 (0) | 2009.02.20 |
|---|
RDPDD.dll 오류로 터미널이 되지 않을때
Windows 2003 을 새로 설치하였는데....
별이유 없이... 터미널이 접속 되지 않을때
이벤트로 로그에
Event Type: Information
Event Source: Application Popup
\SystemRoot\System32\RDPDD.dll failed to load
자꾸만 이런것이 쌓일때
아래의 것을 확인해보세요.
1. VGA 드라이버 재설치
2. 비디오 가속기능을 끈다.
3.레지스트리 설정을 변경
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management]
"SessionImageSize"=dword:00000020
Where 00000020 is hex for 32
'OS, DB > MS Windows' 카테고리의 다른 글
| Windows Live Writer 베타 (2) | 2008.11.11 |
|---|---|
| MS installer 기본 명령줄 인수 (0) | 2008.11.03 |
| 불법 윈도 XP는 '검정 바탕화면' (0) | 2008.09.24 |
| Windows Vista 에서 MSSQL 2005로의 OLE 접속이 무지하게 느릴때.... (0) | 2008.02.13 |
| Windows Vista 쓸만한 기능 – 리소스 모니터 (0) | 2007.08.09 |
불법 윈도 XP는 '검정 바탕화면'
오늘부터 불법 윈도우 XP는 WGA 경고 화면이 표시될꺼라고 하네요.
저와 직접적으로는 별상관없지만...
주변사람들이 이 문제로 골치아프지 않기를 바랍니다.!~
'OS, DB > MS Windows' 카테고리의 다른 글
| Windows Live Writer 베타 (2) | 2008.11.11 |
|---|---|
| MS installer 기본 명령줄 인수 (0) | 2008.11.03 |
| RDPDD.dll 오류로 터미널이 되지 않을때 (0) | 2008.10.08 |
| Windows Vista 에서 MSSQL 2005로의 OLE 접속이 무지하게 느릴때.... (0) | 2008.02.13 |
| Windows Vista 쓸만한 기능 – 리소스 모니터 (0) | 2007.08.09 |
VMWare Linux에서 설치가 안될때...
 invalid-file
invalid-file압축을 해제하고 ./runme.pl
'OS, DB > Linux,Unix' 카테고리의 다른 글
| Fedora 10용 Freshrpm 추가하기 (0) | 2008.12.19 |
|---|---|
| Fedora 10으로 업그레이드 (0) | 2008.12.17 |
| fedora Linux yum 국내 reso (0) | 2007.12.12 |
| 리눅스 데스크탑 소프트웨어 - 피카사... (0) | 2007.12.09 |
| 레드헷 페도라 8... (0) | 2007.12.09 |
Windows Vista 에서 MSSQL 2005로의 OLE 접속이 무지하게 느릴때....
netsh interface tcp set global autotuninglevel=disabled
Thanks suncom..(http://forums.microsoft.com/TechNet/ShowPost.aspx?PostID=2606292&SiteID=17)
이렇게 해야 괜찮아 지더군요.
'OS, DB > MS Windows' 카테고리의 다른 글
| Windows Live Writer 베타 (2) | 2008.11.11 |
|---|---|
| MS installer 기본 명령줄 인수 (0) | 2008.11.03 |
| RDPDD.dll 오류로 터미널이 되지 않을때 (0) | 2008.10.08 |
| 불법 윈도 XP는 '검정 바탕화면' (0) | 2008.09.24 |
| Windows Vista 쓸만한 기능 – 리소스 모니터 (0) | 2007.08.09 |
fedora Linux yum 국내 reso
국내 사이트가 있더군요. 세이클럽에서 지원해주고 있습니다.
ftp://ftp.sayclub.com/pub/fedora/releases/ - 세이클럽
등록해보세요.
설정파일은
/etc/yum.repos.d/
-rw-r--r-- 1 root root 1298 2007-12-12 00:35 fedora-updates.repo
-rw-r--r-- 1 root root 1381 2007-12-12 00:34 fedora.repo
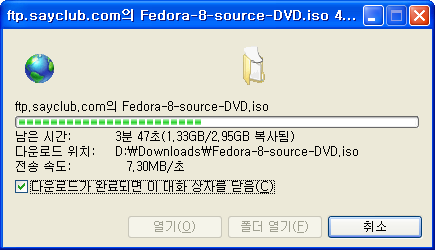
ps. 페도라 8을 가장 빠르게 받을 수 있는 미러사이트도 역시 세이클럽입니다.
ftp://ftp.sayclub.com/pub/fedora/releases/8/Fedora/source/iso/
저희집 속도로 딱 50 Mbps나오더군요...
8분안에 받던데... 괜히 미국사이트에서 3시간이나 받았군...음..
'OS, DB > Linux,Unix' 카테고리의 다른 글
| Fedora 10으로 업그레이드 (0) | 2008.12.17 |
|---|---|
| VMWare Linux에서 설치가 안될때... (0) | 2008.02.20 |
| 리눅스 데스크탑 소프트웨어 - 피카사... (0) | 2007.12.09 |
| 레드헷 페도라 8... (0) | 2007.12.09 |
| yum (Yellow dog Updater, Modified) (0) | 2006.01.02 |
리눅스 데스크탑 소프트웨어 - 피카사...
맞다... 구글의 사진 관리툴이다.
윈도우에서 이것만큼 스피디한 사진툴은 못써본것 같다. 예전 ACDSEE 이런것들이 있었지만
UI도 편하고 기능이 심플하기도 하고 웹으로의 연동도 편리하고....
윈도우용 피카사를 계속 써왔지만 리눅스용은 첨이다. 그럼 이제 리눅스용 피카사를 써보자
우리나라 피카사 다운로드를 아무리 찾아봐도 리눅스 지원에 대한 이야기가 안보인다. 이런...
다시 구글에서 linux,picasa로 검색하니 바로 튀어나온다.
http://picasa.google.com/linux/index.html
이곳에 가니까 리눅스용 피카사에 대해서 나와 있었다.
사용법 및 UI는 윈도우용과 동일했다. 한글은 기본지원은 아닌것 같다.
아직 사진들을 복사하기전이라 피카사의 빠른 브라우징 속도등은 테스트 해보지 못했다.
그리고 한글 메뉴가 없는데.. 이건... 윈도우용에서 파일을 복사해오면 될려나...
디렉토리 구조를 보니 WINE으로 윈도우 모듈들이 돌아가는것 같다.
윈도우에서 한글 메뉴파일을 찾아봐야겠군.....
일단 사진부터 공유해서 가져와야겠다. 일단 삼바 세팅부터.... 해야겠군...
'OS, DB > Linux,Unix' 카테고리의 다른 글
| Fedora 10으로 업그레이드 (0) | 2008.12.17 |
|---|---|
| VMWare Linux에서 설치가 안될때... (0) | 2008.02.20 |
| fedora Linux yum 국내 reso (0) | 2007.12.12 |
| 레드헷 페도라 8... (0) | 2007.12.09 |
| yum (Yellow dog Updater, Modified) (0) | 2006.01.02 |
레드헷 페도라 8...
예전에 운영하다가 중단 된 개인 PC 서버를 복구 하기로 하였다.
오랜만에 리눅스를 다시 잡았더니...모르는게 영 많다.
누구 말대로.. NT를 너무 오래 잡았나?
예전에는 집에 리눅스 데스크탑을 설치해놓으면 뭐뭐뭐뭐 해야지...
기록해 놓은게 있었는데...
자료도 하드가 깨지면서 싹 날라갔더니....
뭐 부터 해야할지가 막막하다....
일단 레드헷 페도라 8을 설치 해보았다...
오호~ 페도라의 발전속도는 참 엄청나다......
이제 리눅스 데스크탑 서버로 쓰면서 리눅스 데스크탑을 가지고 놀아보자^^
다행스럽게 티스토리는 쉽게 이용가능 하다.
'OS, DB > Linux,Unix' 카테고리의 다른 글
| Fedora 10으로 업그레이드 (0) | 2008.12.17 |
|---|---|
| VMWare Linux에서 설치가 안될때... (0) | 2008.02.20 |
| fedora Linux yum 국내 reso (0) | 2007.12.12 |
| 리눅스 데스크탑 소프트웨어 - 피카사... (0) | 2007.12.09 |
| yum (Yellow dog Updater, Modified) (0) | 2006.01.02 |
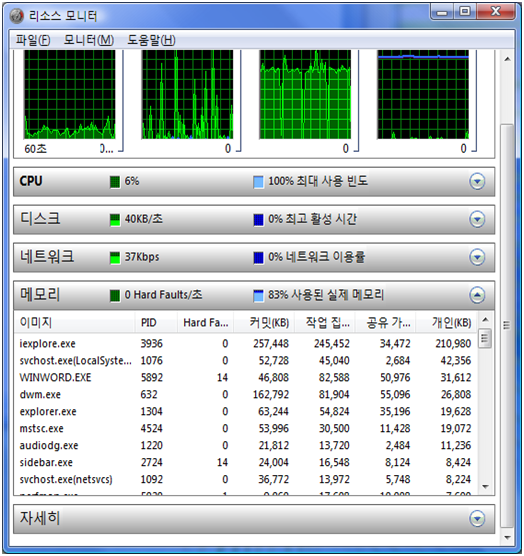
Windows Vista 쓸만한 기능 – 리소스 모니터
윈도우 비스타에서 새로 생긴 기능 중에 쓸만한 기능인 것 같아서 몇 자 적어본다.
바로 요놈 리소스 모니터
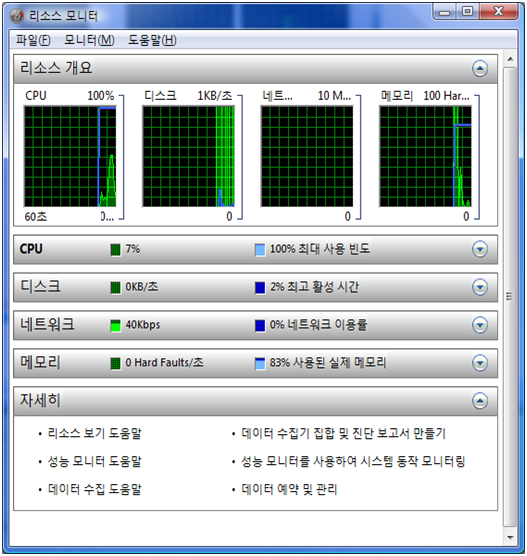
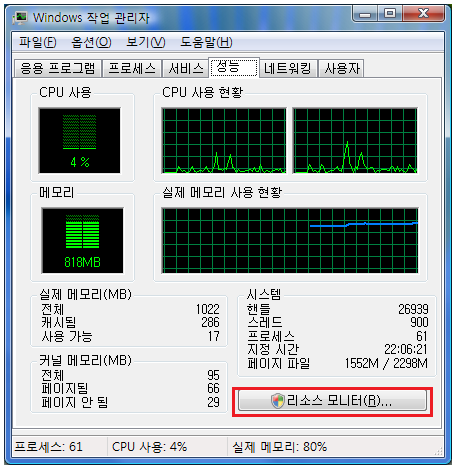
CPU 기존의 작업관리자에서 CPU 사용률을 보기 위해 CPU 정렬을 눌러본 사람은 알것이다.
CPU 사용률이 높았다 낮았다 해서 순서대로 정렬이 안된다는 그래서 평균 CPU를 제공한다.
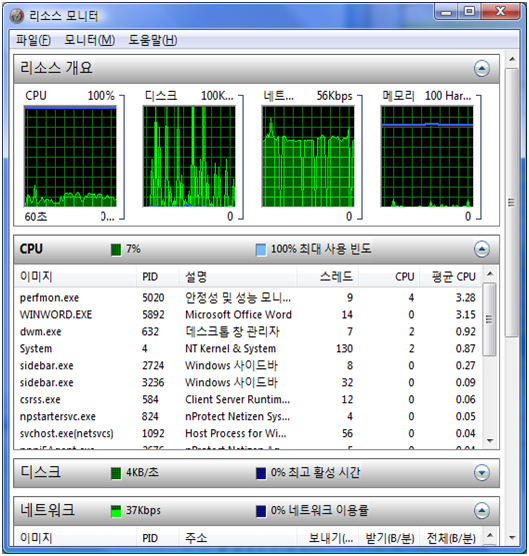
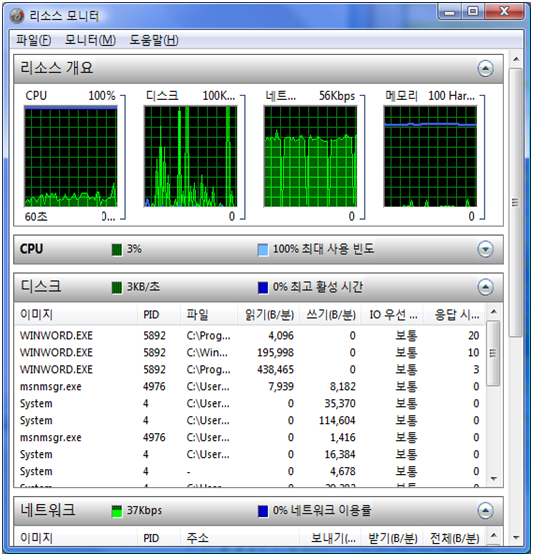
디스크 모니터 프로세스 별 파일 쓰기 읽기 바이트를 보여준다.
네트워크 모니터 –역시 프로세스 별 보내기 받기 Byte를 보여준다.
이 기능 또한 얼마나 필요한 기능이었는지 모른다.
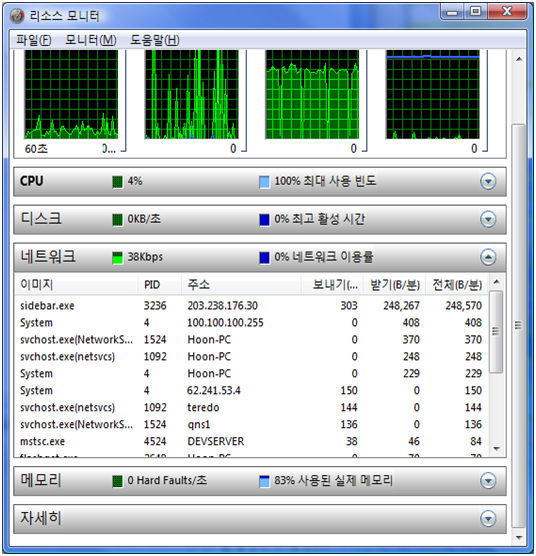
메모리
'OS, DB > MS Windows' 카테고리의 다른 글
| Windows Live Writer 베타 (2) | 2008.11.11 |
|---|---|
| MS installer 기본 명령줄 인수 (0) | 2008.11.03 |
| RDPDD.dll 오류로 터미널이 되지 않을때 (0) | 2008.10.08 |
| 불법 윈도 XP는 '검정 바탕화면' (0) | 2008.09.24 |
| Windows Vista 에서 MSSQL 2005로의 OLE 접속이 무지하게 느릴때.... (0) | 2008.02.13 |
yum (Yellow dog Updater, Modified)
레뎃 9를 쓸 때는 up2date를 사용해서 해당 컴퓨터의 패키지를 업데이트 시켰었는데
레뎃 회원 가입이 잦은 메일.... 3개월 후의 설문 조사 기타 등등이 많이 짜증나게 했었습니다.
그런데 이번에 페도라를 깔면서 yum 업데이트를 알게 되었습니다. 물론 유사한 apt-get있더군요.
yum은 rpm기반으로 자동으로 패키지를 업데이트, 설치, 삭제를 해주는 유틸리티입니다.
rpm의 의존성 문제를 자동적으로 처리하여 쉽게 패키지를 유지 관리할 수 있습니다.
그런데 쉽게 레드햇의 release도 업데이트 할 수 있더군요. 허그덩 왜 몰랐을까나.
거기에 2004년 4월 부로 RedHat 9.0의 모든 업데이트가 중단이 되었죠.
리눅스는 윈도우보다 보안 업데이트랑 관계가 없다라고 생각하신다면 오산입니다.
레뎃이나 페도라 같은 리눅스는 당신이 알고 있는 것보다 훨씬 더 많은 패키지로 구성이 되어 있으므로 어느한곳 손을 놓고 방치하는날에는 당신의 루트는 어느덧.......
사설이 너무길고 일단 설치를 해보지요.
1. 설치
http://linux.duke.edu/projects/yum/download.ptml
방문하십시요.그리고 자신의 release에 맞는 yum을 설치한다.
다운받으셔서 설치하십사요. 페도라의 경우는 제공됩니다.
rpm -Uvh 해당패키지
2. 기본적인 사용 방법
전 패키지를 최신 패키지로 업데이트
# yum update
패키지 신규 설치
# yum install 패키지명[,다수의...]
패키지 업데이트
# yum update 패키지명[,다수의...]
패키지 삭제
# yum remove 패키지명[,다수의...]
3. yum을 이용한 레드햇 release
ftp://ftp.quicknet.nl/pub/Linux/ftp.redhat.com/
에서 업그레이드 하고 싶은 버전의 redhat-release***.rpm을 받아서 설치
# yum upgrade
자세한 이용법은
http://www.linux.duke.edu/projects/yum
그리고 #ntsysv yum을 켜 두시면 저녁 시간에 지가 알아서 헤더 파일을 받아 놓는 것 같네요.
물론 자동 업데이트가 불안하신 분은 안 켜 두시면 됩니다. 그럼 이만...
2006년 하늘높이 씀
'OS, DB > Linux,Unix' 카테고리의 다른 글
| Fedora 10으로 업그레이드 (0) | 2008.12.17 |
|---|---|
| VMWare Linux에서 설치가 안될때... (0) | 2008.02.20 |
| fedora Linux yum 국내 reso (0) | 2007.12.12 |
| 리눅스 데스크탑 소프트웨어 - 피카사... (0) | 2007.12.09 |
| 레드헷 페도라 8... (0) | 2007.12.09 |
